Persisted Queries
Usa consultas GraphQL para crear endpoints predefinidos como en REST, obteniendo los beneficios de ambas APIs.
Descripción
Con REST, creas múltiples endpoints, cada uno devolviendo un conjunto predefinido de datos.
| Ventajas | Desventajas |
|---|---|
| ✅ Es simple | ❌ Es tedioso crear todos los endpoints |
✅ Se accede mediante GET o POST | ❌ Un proyecto puede sufrir cuellos de botella esperando a que los endpoints estén listos |
| ✅ Se puede cachear en el servidor o CDN | ❌ Producir documentación es obligatorio |
| ✅ Es seguro: solo se exponen los datos previstos | ❌ Puede ser lento (principalmente para apps móviles), ya que la aplicación puede necesitar varias peticiones para obtener todos los datos |
Con GraphQL, proporcionas cualquier consulta a un único endpoint, que devuelve exactamente los datos solicitados.
| Ventajas | Desventajas |
|---|---|
| ✅ No hay under/over fetching de datos | ❌ Solo se accede mediante POST |
| ✅ Puede ser rápido, ya que todos los datos se obtienen en una única petición | ❌ No se puede cachear en el servidor o CDN, lo que lo hace más lento y caro de lo que podría ser |
| ✅ Permite iterar rápidamente el proyecto | ❌ Puede requerir reinventar la rueda, como subir archivos o cachear |
| ✅ Puede ser auto-documentado | ❌ Hay que lidiar con complejidades adicionales, como el problema N+1 |
| ✅ Proporciona un editor para la consulta (GraphiQL) que simplifica la tarea |
Las persisted queries combinan estos 2 enfoques:
- Utilizan GraphQL para crear y resolver consultas
- Pero en lugar de exponer un único endpoint, exponen cada consulta predefinida bajo su propio endpoint
Por tanto, obtenemos múltiples endpoints con datos predefinidos, como en REST, pero creados utilizando GraphQL, obteniendo las ventajas de cada uno y evitando sus desventajas:
| Ventajas | Desventajas |
|---|---|
✅ Se accede mediante GET o POST | |
| ✅ Se puede cachear en el servidor o CDN | |
| ✅ Es seguro: solo se exponen los datos previstos | |
| ✅ No hay under/over fetching de datos | |
| ✅ Puede ser rápido, ya que todos los datos se obtienen en una única petición | POST |
| ✅ Permite iterar rápidamente el proyecto | |
| ✅ Puede ser auto-documentado | |
| ✅ Proporciona un editor para la consulta (GraphiQL) que simplifica la tarea |

Ejecutando la Persisted Query
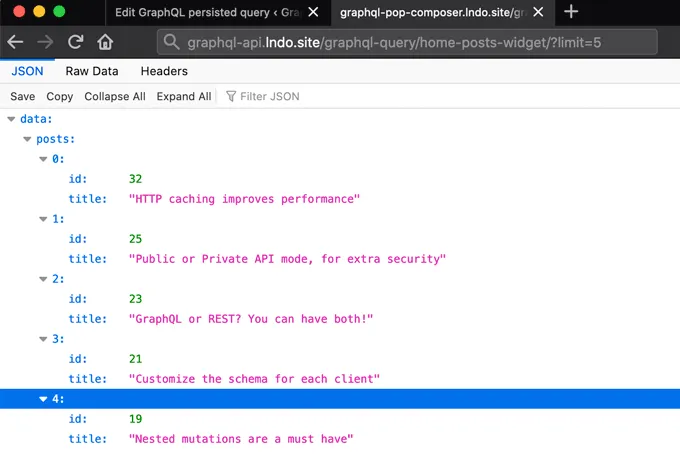
Una vez que la persisted query se publica, podemos ejecutarla mediante su permalink.
La persisted query puede ejecutarse directamente en el navegador, ya que se accede mediante GET, y obtendremos los datos solicitados en formato JSON:
Creando una Persisted Query
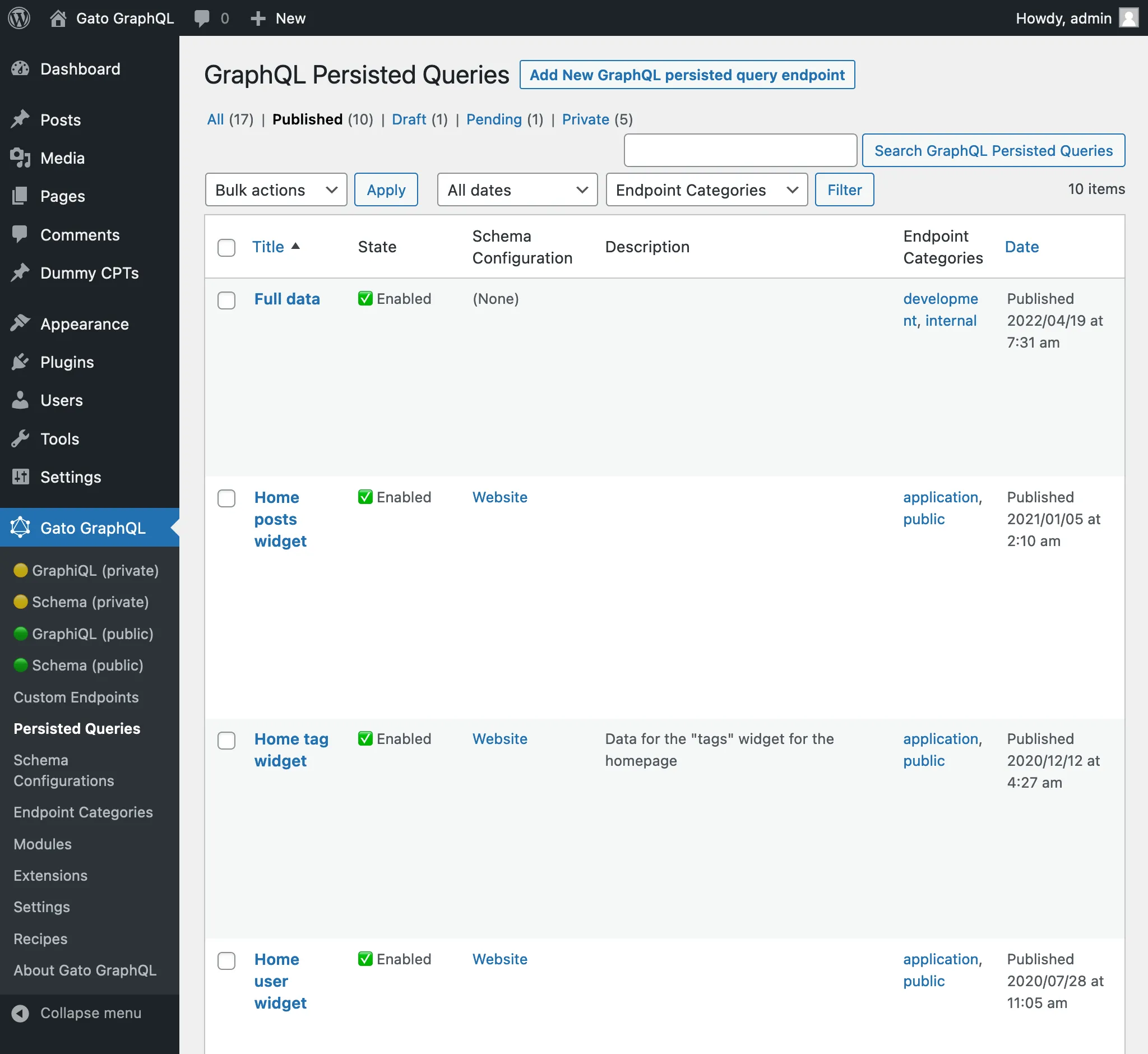
Al hacer clic en el enlace Persisted Queries del menú, se muestra la lista de todas las persisted queries creadas:
Una persisted query es un custom post type (CPT). Para crear una nueva persisted query, haz clic en el botón "Añadir Nueva persisted query GraphQL", lo que abrirá el editor de WordPress:
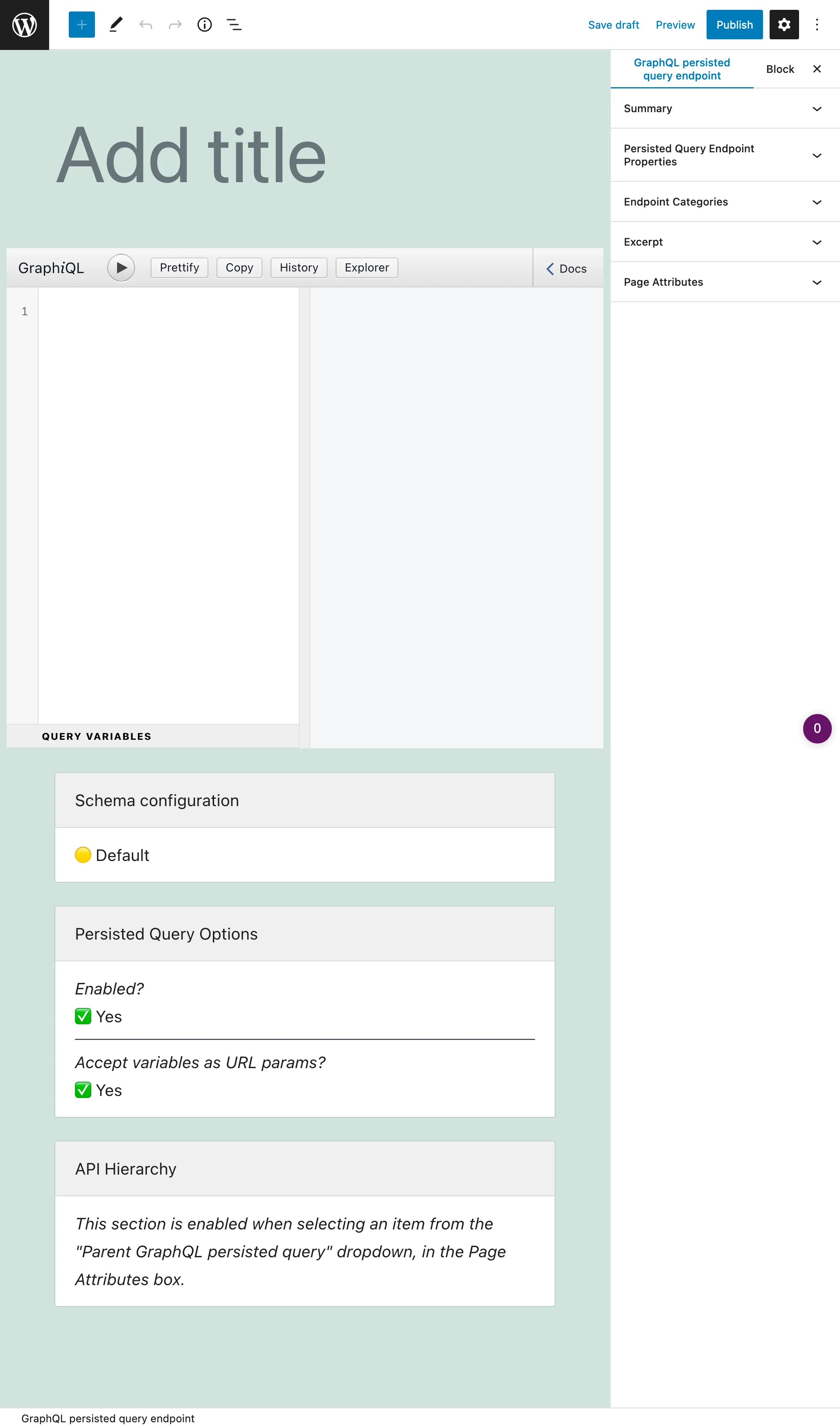
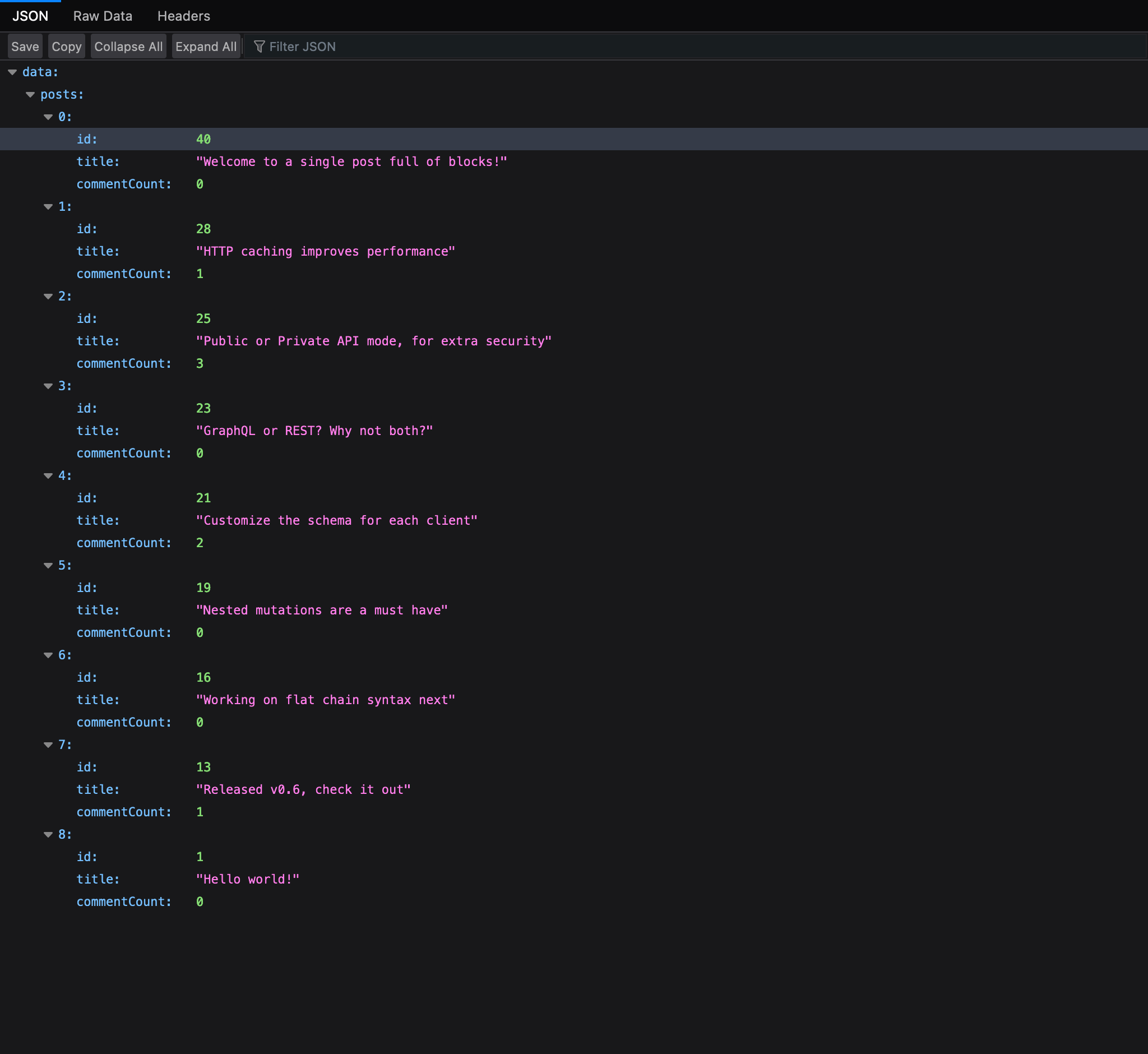
La entrada principal es el cliente GraphiQL, que viene con el Explorer por defecto. Hacer clic en los campos del panel lateral izquierdo los añade a la consulta, y hacer clic en el botón "Run" ejecuta la consulta:

Cuando la consulta está lista, publícala, y su permalink se convertirá en su endpoint. El enlace al endpoint (y al source) se muestra en el panel lateral "Resumen del Endpoint de Persisted Query":
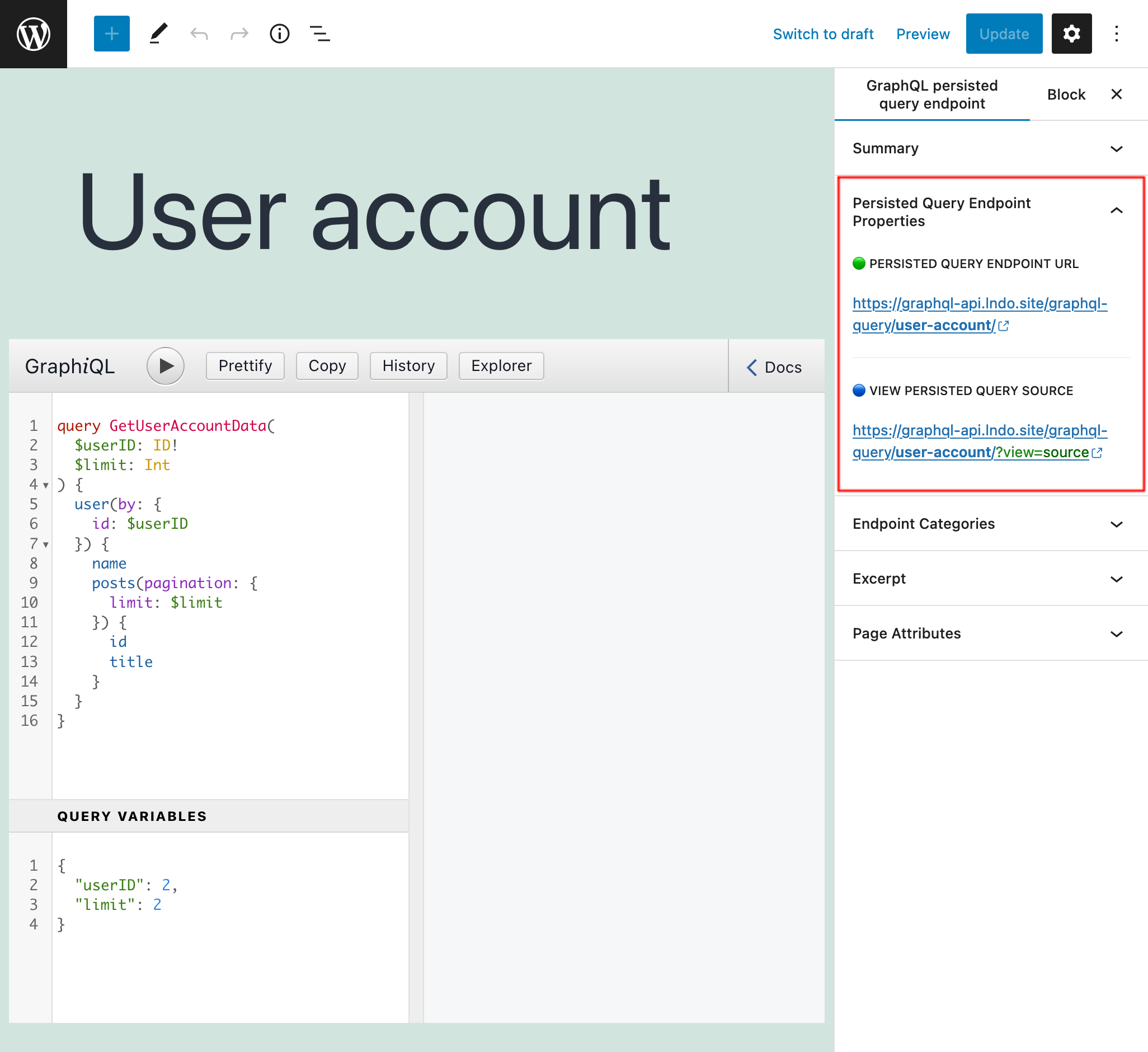
Añadiendo ?view=source al permalink, se mostrará la persisted query y su configuración (siempre que el usuario haya iniciado sesión y el rol del usuario tenga acceso):

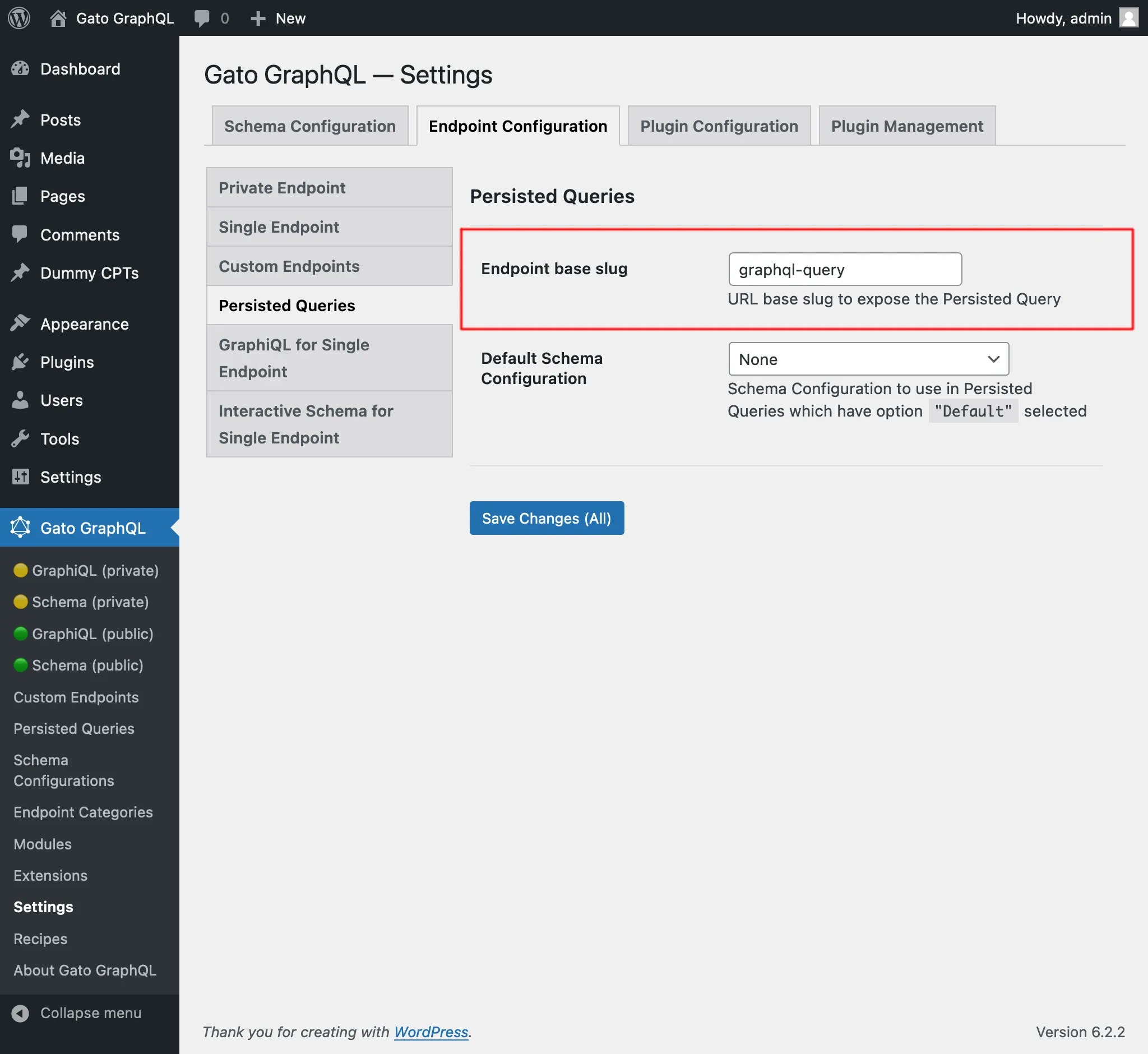
Por defecto, el endpoint de la persisted query tiene la ruta /graphql-query/, y este valor es configurable mediante los Ajustes:
Configuración del esquema
La definición de qué elementos contiene el esquema, y qué acceso tendrán los usuarios al mismo, se define en la configuración del esquema.
Por tanto, debemos crear una configuración del esquema, y luego seleccionarla desde el desplegable:

Organizando Persisted Queries por Categoría
En el panel lateral "Categorías de endpoint" podemos añadir categorías para ayudar a gestionar la Persisted Query:
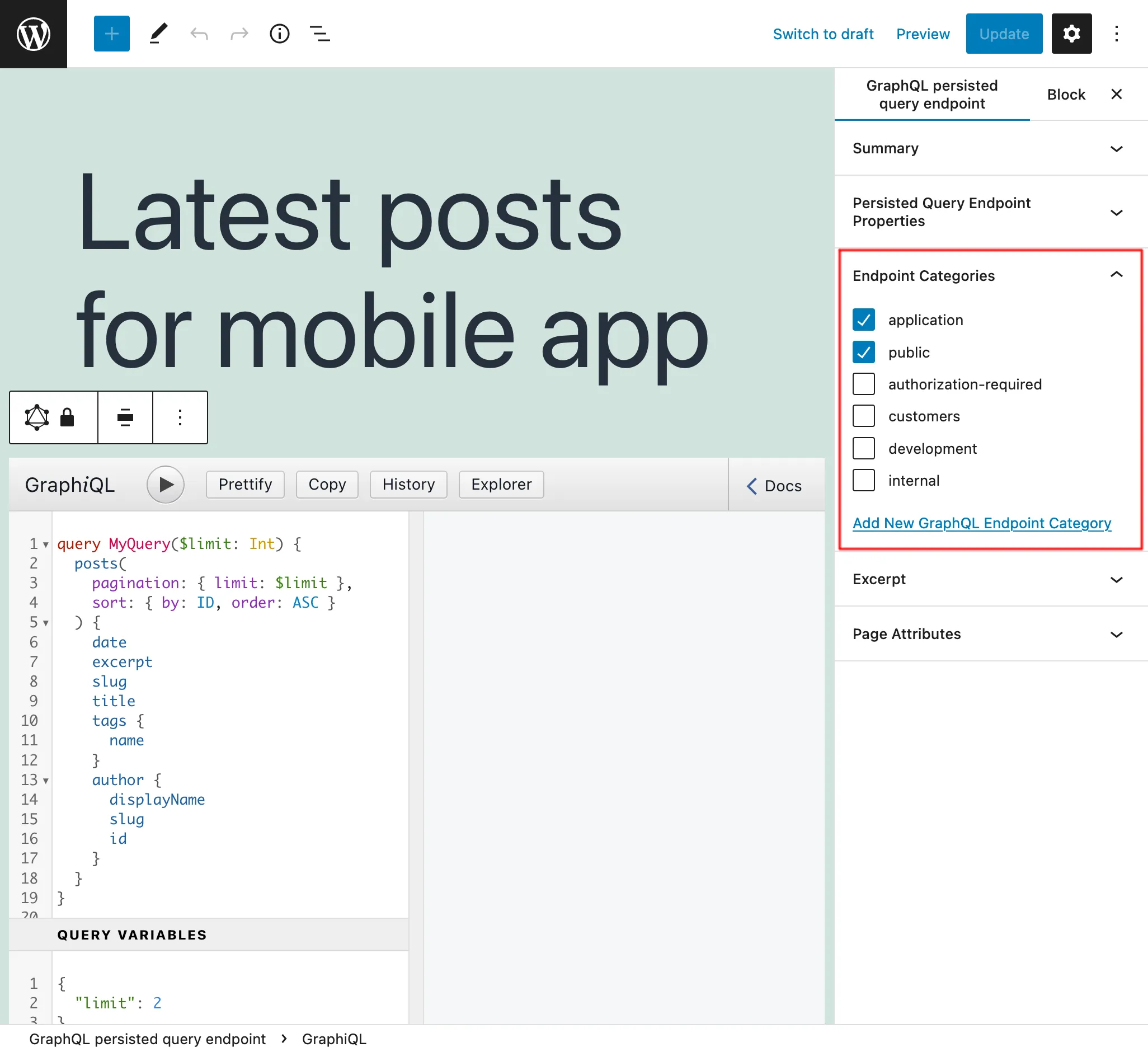
Por ejemplo, podemos crear categorías para gestionar endpoints por cliente, aplicación, o cualquier otra información necesaria:

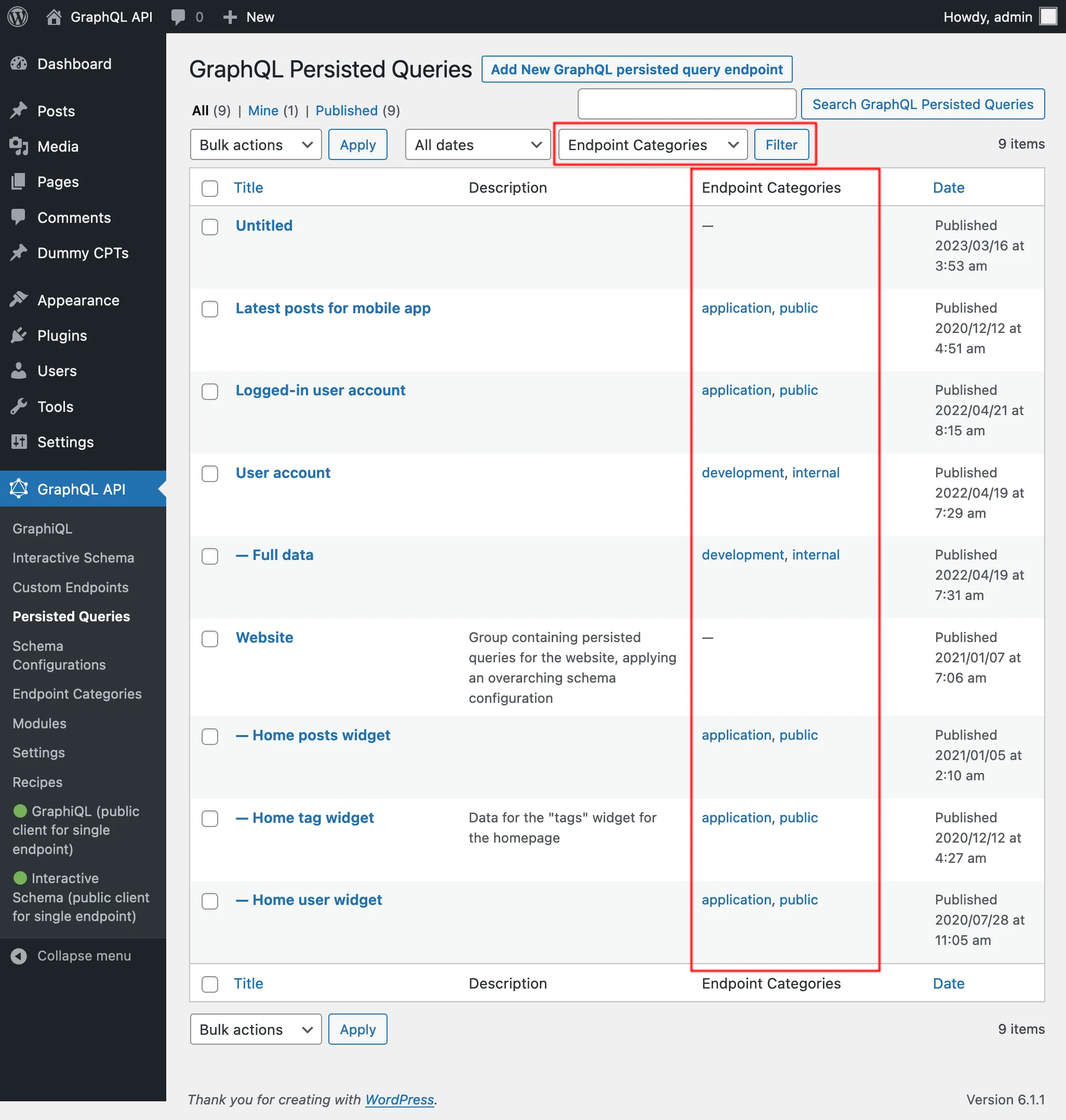
En la lista de Persisted Queries podemos visualizar sus categorías y, haciendo clic en cualquier enlace de categoría, o usando el filtro de la parte superior, solo se mostrarán todas las entradas de esa categoría:
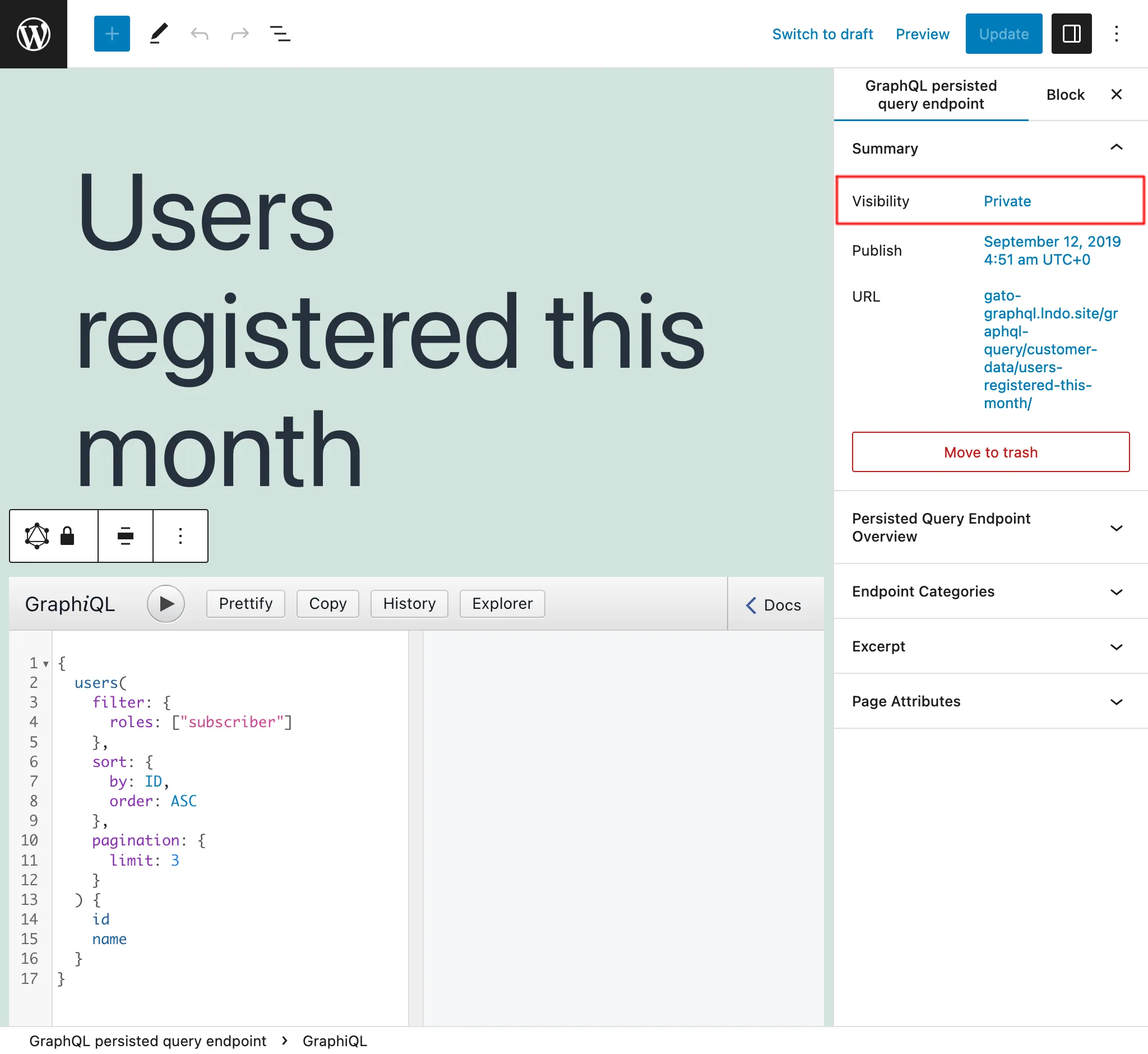
Persisted queries privadas
Estableciendo el estado de la Persisted Query como private, el endpoint solo podrá ser accedido por el usuario administrador. Esto evita que nuestros datos sean compartidos involuntariamente con usuarios que no deben tener acceso a ellos.
Por ejemplo, podemos crear Persisted Queries privadas que ayuden a gestionar la aplicación, como obtener datos para crear informes con nuestras métricas.
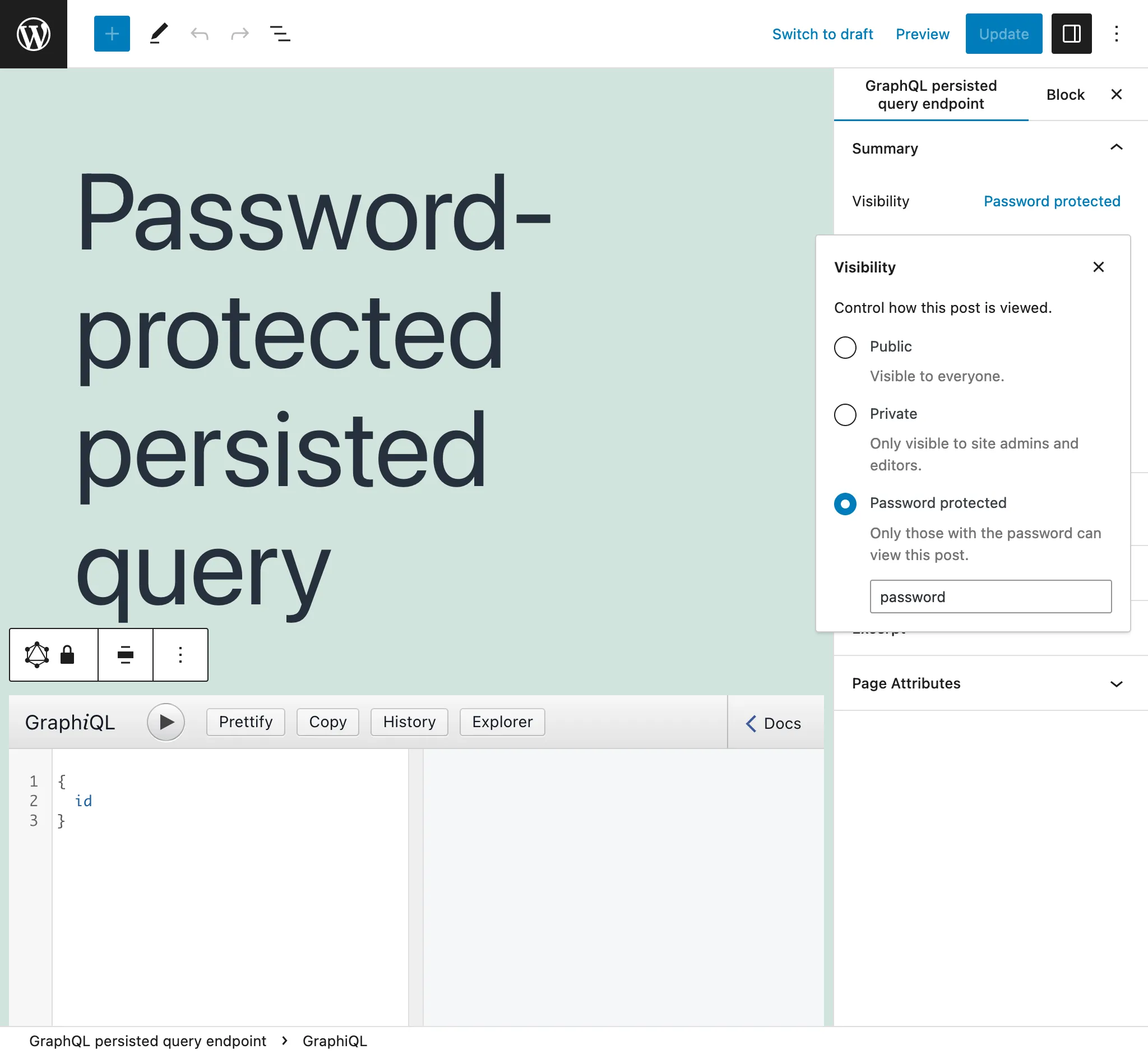
Persisted queries protegidas con contraseña
Si creamos una Persisted Query para un cliente específico, podemos asignarle una contraseña, para proporcionar un nivel adicional de seguridad y que solo ese cliente acceda al endpoint.
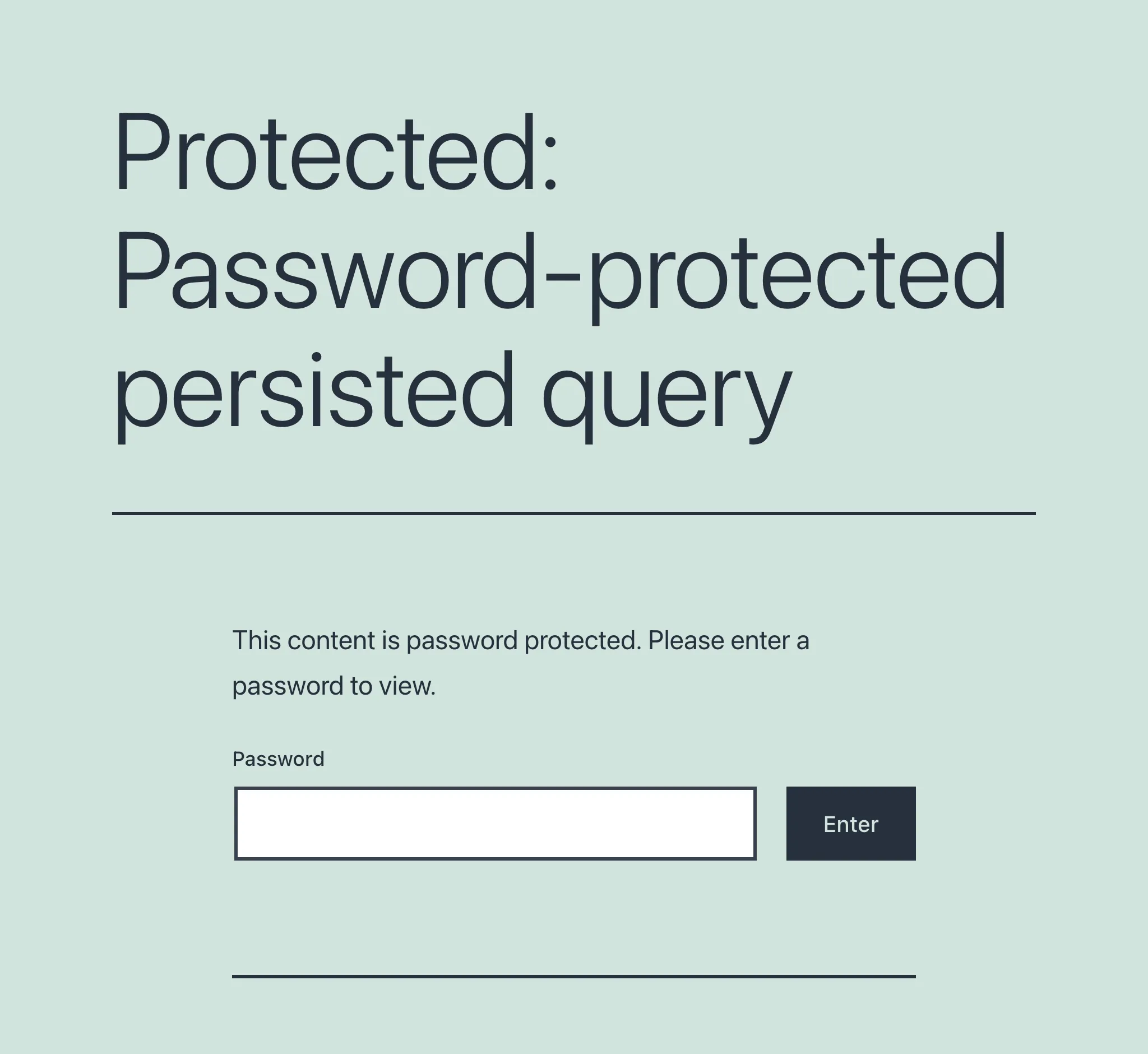
Cuando se accede por primera vez a una persisted query protegida con contraseña, nos encontramos con una pantalla que solicita la contraseña:
Una vez que se proporciona y valida la contraseña, solo entonces el usuario accederá al endpoint previsto.
Haciendo dinámica la persisted query mediante parámetros URL
El valor para cada variable puede establecerse mediante un parámetro URL (con el nombre de la variable) al ejecutar la persisted query. Si la opción "¿Anulan los parámetros URL a las variables?" está habilitada, entonces el parámetro URL tendrá prioridad. De lo contrario, el valor definido en el diccionario de variables tendrá prioridad (si existe).
Por ejemplo, en esta consulta, el número de resultados se controla mediante la variable $limit, con un valor por defecto de 3:
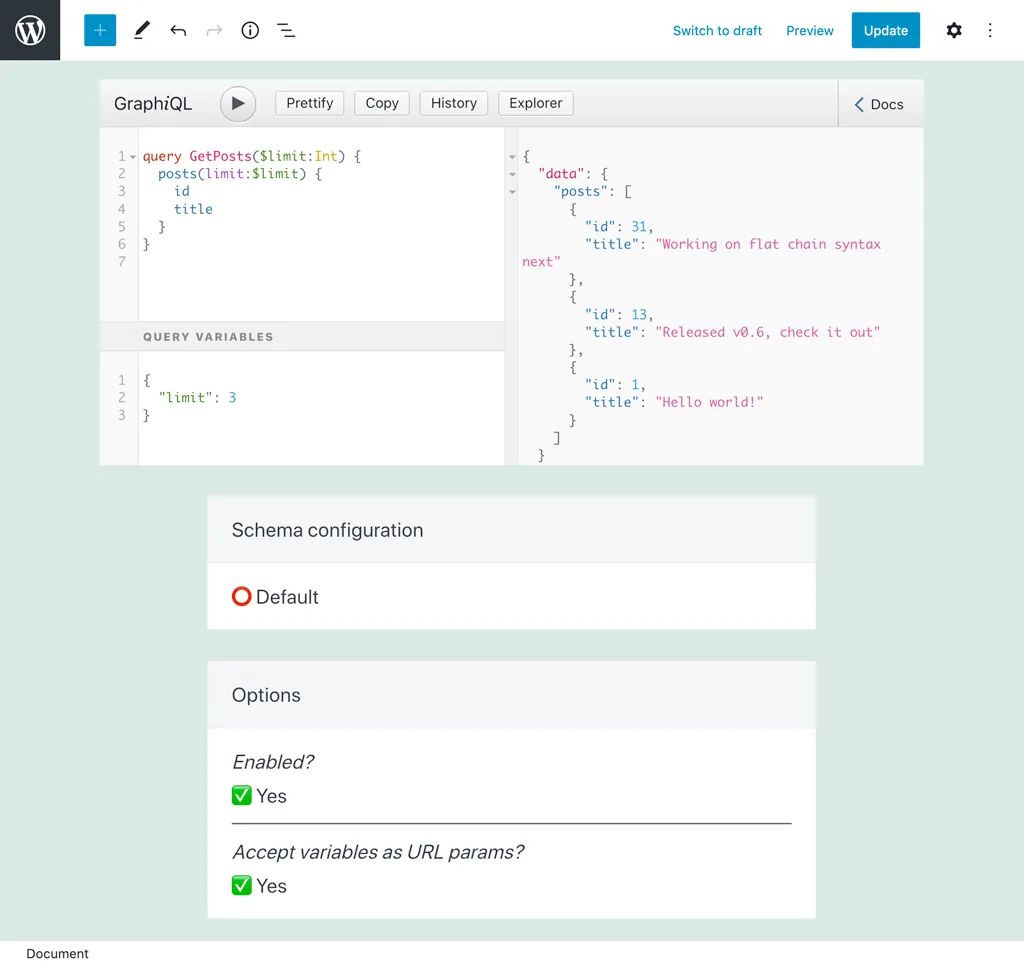
Al ejecutar esta persisted query, pasando ?limit=5 ejecutará la consulta devolviendo 5 resultados: