
Motor de carga de datos
Gato GraphQL utiliza componentes en el lado del servidor para representar el modelo de datos (no grafos ni árboles). Veamos cómo ejecuta el proceso de carga de datos para resolver la consulta GraphQL.
Para procesar los datos, debemos aplanar los componentes en tipos (<FeaturedDirector> => Director, <Film> => Film, <Actor> => Actor), ordenarlos según aparecieron en la jerarquía de componentes (Director, después Film, después Actor) y tratarlos por "iteraciones", recuperando los datos de los objetos para cada tipo en su propia iteración, así:

El motor de carga de datos del servidor debe implementar el siguiente (pseudo-)algoritmo para cargar los datos:
Preparación:
- Preparar una cola vacía para almacenar la lista de IDs de los objetos que deben recuperarse de la base de datos, organizados por tipo (cada entrada será:
[tipo => lista de IDs]) - Recuperar el ID del objeto director destacado y colocarlo en la cola bajo el tipo
Director
Bucle hasta que no haya más entradas en la cola:
- Obtener la primera entrada de la cola: el tipo y la lista de IDs (por ejemplo:
Directory[2]), y eliminar esta entrada de la cola - Utilizando el objeto
TypeDataLoaderdel tipo, ejecutar una única consulta contra la base de datos para recuperar todos los objetos de ese tipo con esos IDs - Si el tipo tiene campos relacionales (por ejemplo: el tipo
Directortiene el campo relacionalfilmsde tipoFilm), entonces recoger todos los IDs de esos campos de todos los objetos recuperados en la iteración actual (por ejemplo: todos los IDs del campofilmsde todos los objetos de tipoDirector), y colocar esos IDs en la cola bajo el tipo correspondiente (por ejemplo: los IDs[3, 8]bajo el tipoFilm).
Al finalizar las iteraciones, habremos cargado todos los datos de objetos para todos los tipos, así:
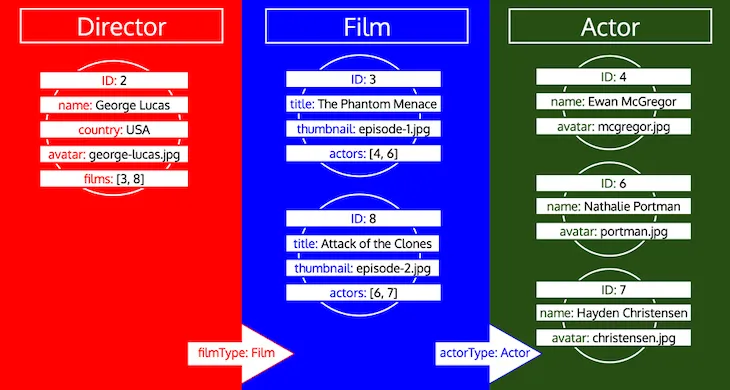
Fíjate en cómo se recogen todos los IDs de un tipo hasta que ese tipo es procesado en la cola. Si, por ejemplo, añadimos un campo relacional preferredActors al tipo Director, esos IDs se añadirían a la cola bajo el tipo Actor, y se procesarían junto con los IDs del campo actors del tipo Film:
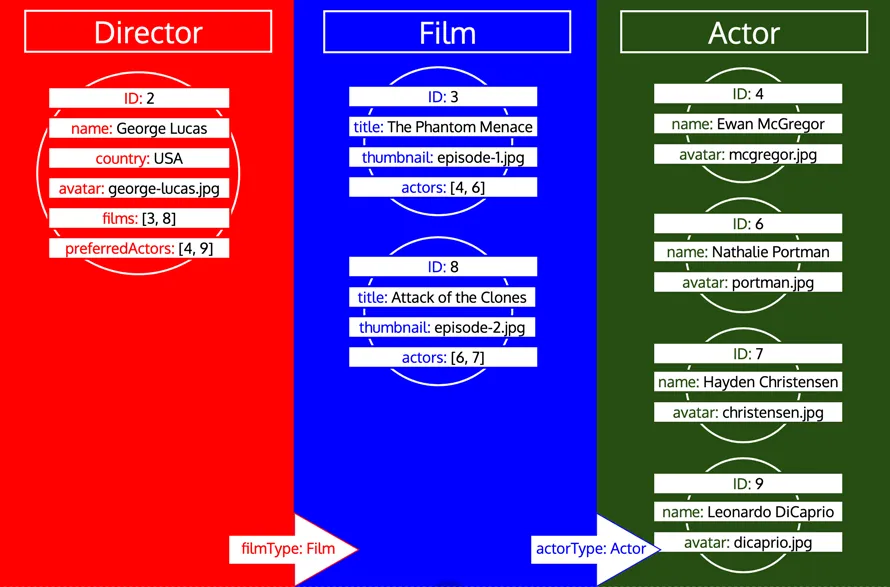
Sin embargo, si un tipo ya ha sido procesado y entonces necesitamos cargar más datos de ese tipo, se trata de una nueva iteración sobre ese tipo. Por ejemplo, añadir un campo relacional preferredDirector al tipo Author hará que el tipo Director se añada de nuevo a la cola:
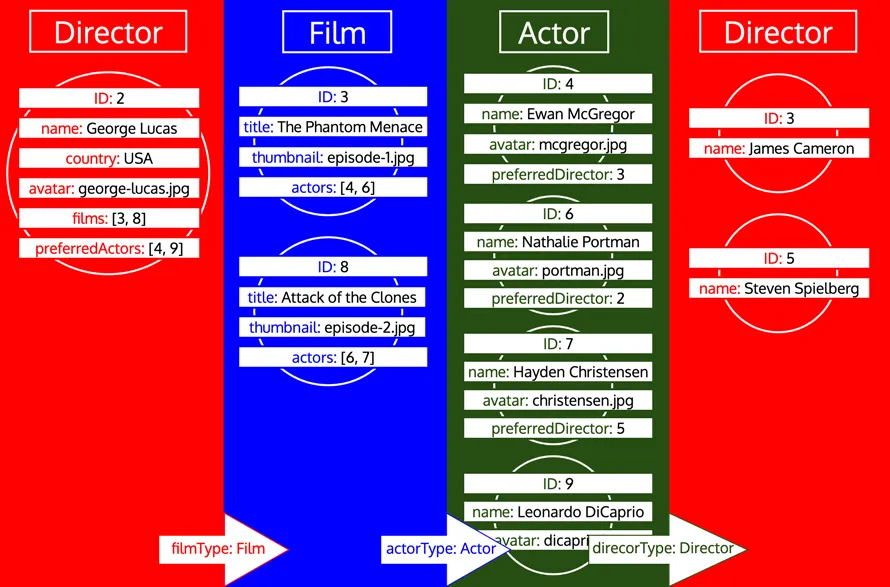
Ahora que ya hemos recuperado todos los datos de los objetos, necesitamos darles la forma de la respuesta esperada, reflejando la consulta GraphQL. Sin embargo, como puede verse, los datos no tienen la estructura de árbol requerida. En su lugar, los campos relacionales contienen los IDs del objeto anidado, emulando cómo se representan los datos en una base de datos relacional. Por lo tanto, siguiendo esta comparación, los datos recuperados para cada tipo pueden representarse como una tabla, así:
Tabla para el tipo Director:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
Tabla para el tipo Film:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
Tabla para el tipo Actor:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
Con todos los datos organizados en tablas, y sabiendo cómo se relaciona cada tipo con los demás (es decir, Director referencia a Film a través del campo films, Film referencia a Actor a través del campo actors), el servidor GraphQL puede convertir fácilmente los datos en la forma de árbol esperada:
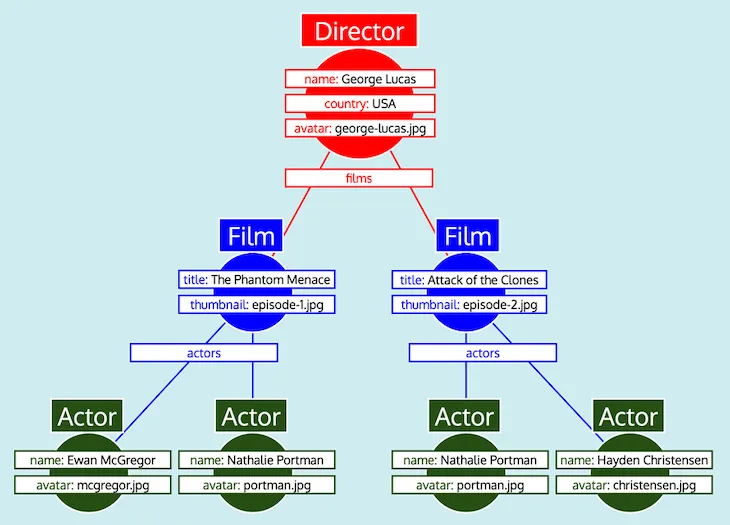
Por último, el servidor GraphQL emite el árbol, que tiene la forma de la respuesta esperada:
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}Analizando la complejidad temporal de la solución
Analicemos la notación O grande del algoritmo de carga de datos para entender cómo crece el número de consultas ejecutadas contra la base de datos a medida que aumenta el número de entradas, y así asegurarnos de que esta solución es eficiente.
El motor de carga de datos carga los datos en iteraciones que se corresponden con cada tipo. Cuando inicia una iteración, ya tendrá la lista de todos los IDs de todos los objetos que debe recuperar, por lo que puede ejecutar una única consulta para obtener todos los datos de los objetos correspondientes. De ahí se deduce que el número de consultas a la base de datos crecerá de manera lineal con el número de tipos involucrados en la consulta. En otras palabras, la complejidad temporal es O(n), donde n es el número de tipos en la consulta (sin embargo, si un tipo se itera más de una vez, debe añadirse más de una vez a n).
Esta solución es muy eficiente, mucho mejor que la complejidad exponencial que cabría esperar al tratar con grafos, o la complejidad logarítmica que cabría esperar al tratar con árboles.
Código PHP implementado
El proceso de carga de datos tiene lugar en la función getComponentData de la clase Engine del paquete Component Model.