
Manipulando el orden de resolución de campos
El objetivo de la directiva @export proporcionada por Ejecución de múltiples consultas es exportar el valor de un campo (o conjunto de campos) a una variable, para utilizarlo en otro lugar de la consulta.
Esta directiva no funcionaría si la lectura de la variable se produjera antes de exportar el valor a dicha variable. Por lo tanto, el motor necesita proporcionar una forma de controlar el orden de ejecución de los campos.
Gato GraphQL ofrece una forma de manipular el orden de ejecución de los campos a través de la propia consulta. El motor carga los datos en iteraciones para cada tipo, resolviendo primero todos los campos del primer tipo que encuentra en la consulta, luego todos los campos del segundo tipo, y así sucesivamente hasta que no quedan más tipos por procesar.
Por ejemplo, la siguiente consulta, que involucra objetos de tipo Director, Film y Actor:
{
directors {
name
films {
title
actors {
name
}
}
}
}...es resuelta por el motor GraphQL en este orden:

Si, después de procesarse, un tipo vuelve a aparecer referenciado en la consulta para recuperar datos no cargados (por ejemplo: de objetos adicionales, o de campos adicionales de objetos ya cargados), entonces el tipo se añade de nuevo al final de la lista de iteración.
Por ejemplo, si también consultamos el campo preferredDirector del Actor (que devuelve un objeto de tipo Director) así:
{
directors {
name
films {
title
actors {
name
preferredDirector {
name
}
}
}
}
}...entonces el motor GraphQL procesa la consulta en este orden:

Veamos cómo se aplica esto a la ejecución de @export en una sola consulta. En nuestro primer intento, creamos la consulta como lo haríamos normalmente, sin pensar en el orden de ejecución de los campos:
query GetPostsAuthorNames {
user(by: { id: 1 }) {
name @export(as: "authorName")
}
posts(filter: { search: $authorName }) {
id
title
}
}Al ejecutar la consulta, produce esta respuesta:
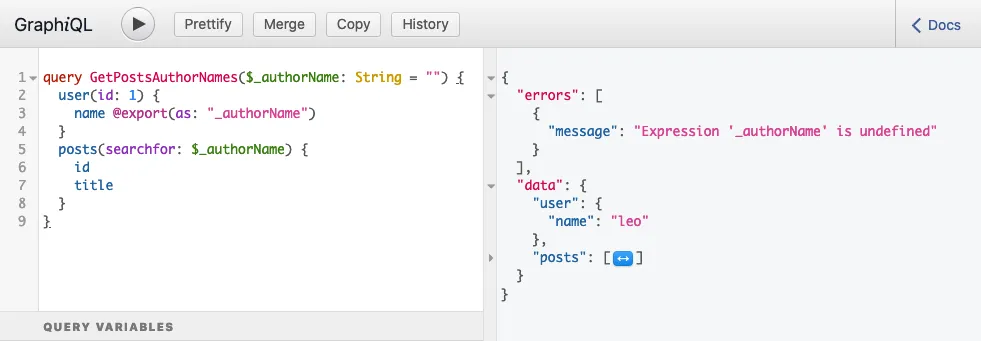
...que contiene el siguiente error:
{
"errors": [
{
"message": "Expression 'authorName' is undefined",
}
]
}Este error significa que, en el momento en que se leyó la variable $authorName, aún no había sido establecida; estaba undefined.
Veamos por qué ocurre esto. Primero, analicemos qué tipos aparecen en la consulta, añadidos como comentarios a continuación:
# Type: Root
query GetPostsAuthorNames {
# Type: User
user(by: {id: 1}) {
# Type: String
name @export(as: "authorName")
}
# Type: Post
posts(filter: { search: $authorName }) {
# Type: ID
id
# Type: String
title
}
}Para procesar los tipos y cargar sus datos, el motor de carga de datos añade el tipo de la consulta Root a una lista FIFO (First-In, First-Out, "primero en entrar, primero en salir"), siendo así [Root] la lista inicial que se pasa al algoritmo, y luego itera sobre los tipos de forma secuencial, así:
| # | Operación | Lista |
|---|---|---|
| 0 | Preparar lista FIFO | [Root] |
| 1a | Sacar el primer tipo de la lista (Root) | [] |
| 1b | Procesar todos los campos consultados del tipo Root:→ user(by: {id: 1})→ posts(filter: { search: $authorName })Añadir sus tipos ( User y Post) a la lista | [User, Post] |
| 2a | Sacar el primer tipo de la lista (User) | [Post] |
| 2b | Procesar el campo consultado del tipo User:→ name @export(as: "authorName")Como es un tipo escalar ( String), no hace falta añadirlo a la lista | [Post] |
| 3a | Sacar el primer tipo de la lista (Post) | [] |
| 3b | Procesar todos los campos consultados del tipo Post:→ id→ titleComo son tipos escalares ( ID y String), no hace falta añadirlos a la lista | [] |
| 4 | La lista está vacía, la iteración termina. |
Aquí podemos ver el problema: @export se ejecuta en el paso 2b, pero se leyó en el paso 1b.
Es aquí donde necesitamos controlar el flujo de ejecución de los campos. La solución implementada consiste en retrasar el momento en que se lee la variable exportada, lo que se consigue consultando artificialmente el campo self del tipo Root.
El campo self, como su nombre indica, devuelve el mismo objeto; aplicado al objeto Root, devuelve el mismo objeto Root. Puede que te preguntes: "si ya tengo el objeto raíz, ¿por qué necesitaría recuperarlo de nuevo?". Porque entonces el algoritmo del motor tendrá que añadir esta nueva referencia a Root al final de la lista FIFO, y podemos distribuir deliberadamente los campos consultados antes o después de cada una de esas iteraciones.
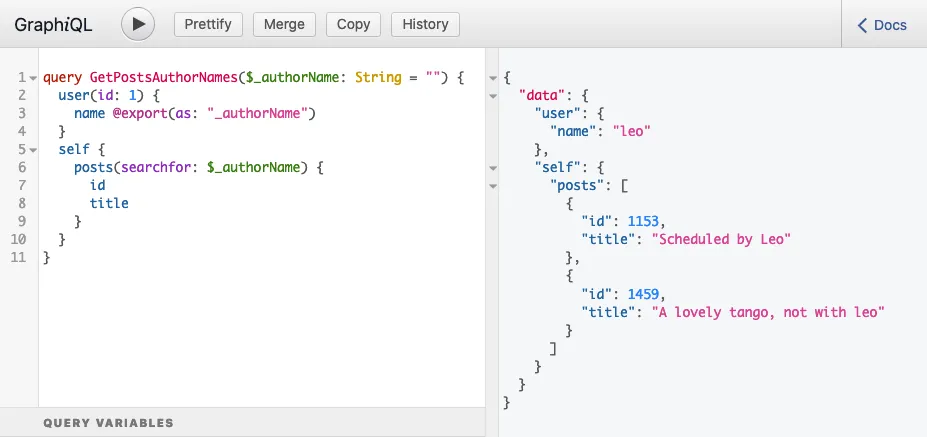
Por eso el campo posts(filter:{ search: $authorName }) se coloca dentro de un campo self en la consulta de arriba, y al ejecutar la consulta se produce la respuesta esperada:
query GetPostsAuthorNames {
user(by: {id: 1}) {
name @export(as: "authorName")
}
self {
posts(filter: { search: $authorName }) {
id
title
}
}
}
Exploremos el orden en que se procesan los tipos para esta consulta, para entender por qué funciona bien:
| # | Operación | Lista |
|---|---|---|
| 0 | Preparar lista FIFO | [Root] |
| 1a | Sacar el primer tipo de la lista (Root) | [] |
| 1b | Procesar todos los campos consultados del tipo Root:→ user(by: {id: 1})→ selfAñadir sus tipos ( User y Root) a la lista | [User, Root] |
| 2a | Sacar el primer tipo de la lista (User) | [Root] |
| 2b | Procesar el campo consultado del tipo User:→ name @export(as: "authorName")Como es un tipo escalar ( String), no hace falta añadirlo a la lista | [Root] |
| 3a | Sacar el primer tipo de la lista (Root) | [] |
| 3b | Procesar el campo consultado del tipo Root:→ posts(filter:{ search: $authorName })Añadir su tipo ( Post) a la lista | [Post] |
| 4a | Sacar el primer tipo de la lista (Post) | [] |
| 4b | Procesar todos los campos consultados del tipo Post:→ id→ titleComo son tipos escalares ( ID y String), no hace falta añadirlos a la lista | [] |
| 5 | La lista está vacía, la iteración termina. |
Ahora podemos ver que el problema se ha resuelto: @export se ejecuta en el paso 2b y se lee en el paso 3b.
Multiple Query Execution hace exactamente esto al desacoplar consultas: convierte el documento GraphQL añadiendo campos self, de modo que los campos de cada operación se ejecuten solo después de que se hayan resuelto todos los campos de todas las operaciones anteriores.