
Pipeline de directivas
Las directivas se colocan en un pipeline y se ejecutan en orden. Su diseño inicial es sencillo, así:

En esta arquitectura:
- La entrada del pipeline es el valor del campo proporcionado por el resolver de campo
- Cada directiva ejecuta su lógica y pasa el resultado a la siguiente directiva del pipeline
- La salida del pipeline será el valor del campo resuelto, tras haber sido procesado por todas las directivas
Sin embargo, esta arquitectura no aprovecha al máximo GraphQL. A continuación se describen todas las etapas del pipeline de directivas real, hasta llegar al diseño realmente implementado en Gato GraphQL.
Las directivas como bloques de construcción de la resolución de la consulta
Inicialmente podríamos plantearnos que el servidor GraphQL resolviera el campo mediante algún mecanismo y, después, pasara este valor como entrada al pipeline de directivas.
Sin embargo, es mucho más sencillo disponer de un único mecanismo que gestione todo: invocar a los resolvers de campo (tanto para validar campos como para resolverlos) puede hacerse ya a través del pipeline de directivas. En este caso, el pipeline de directivas es el único mecanismo utilizado para resolver la consulta.
Por esta razón, el servidor Gato GraphQL incorpora dos directivas especiales:
@validatellama al resolver de campo para validar que el campo se puede resolver (por ejemplo: que la sintaxis es correcta, que el campo existe, etc.)- Si la validación tiene éxito,
@resolveValueAndMergellama entonces al resolver de campo para resolver el campo, y fusiona el valor en el objeto de respuesta
Estas dos son del tipo especial de directivas "de sistema": están reservadas exclusivamente al motor de GraphQL y son implícitas en cada campo. (Por el contrario, las directivas estándar son explícitas: las añade el usuario a la consulta.)
Utilizando estas dos directivas, esta consulta:
query {
field1
field2 @directiveA
}...se resolverá como esta otra:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}El pipeline tiene ahora este aspecto (ten en cuenta que el pipeline recibe el campo como entrada, no su valor resuelto inicial):

Slots del pipeline
Las directivas normalmente se ejecutan después de @resolveValueAndMerge, ya que lo más probable es que impliquen actualizar el valor del campo resuelto. Sin embargo, hay otras directivas que deben ejecutarse antes de @validate, o entre @validate y @resolveValueAndMerge.
Por ejemplo:
- Para medir el tiempo que se tarda en resolver un campo, la directiva
@traceExecutionTimepuede obtener la hora actual antes y después de resolver el campo, colocando las subdirectivas@startTracingExecutionTimeal principio y@endTracingExecutionTimeal final del pipeline - Una directiva
@cachedebe comprobar si un campo solicitado está en caché y devolver ya esa respuesta, antes de ejecutar@resolveValueAndMerge
El pipeline ofrecerá entonces cinco slots distintos a través de la clase PipelinePositions, y la directiva indicará en cuál de ellos debe ejecutarse:
- El slot
"beginning": al principio de todo - El slot
"before-validate": antes de que tenga lugar la validación - El slot
"middle": tras la validación y antes de la resolución del campo - El slot
"after-resolve": tras la resolución del campo - El slot
"end": al final de todo
El pipeline de directivas tiene ahora este aspecto (considerando solo 3 etapas, por simplificar):

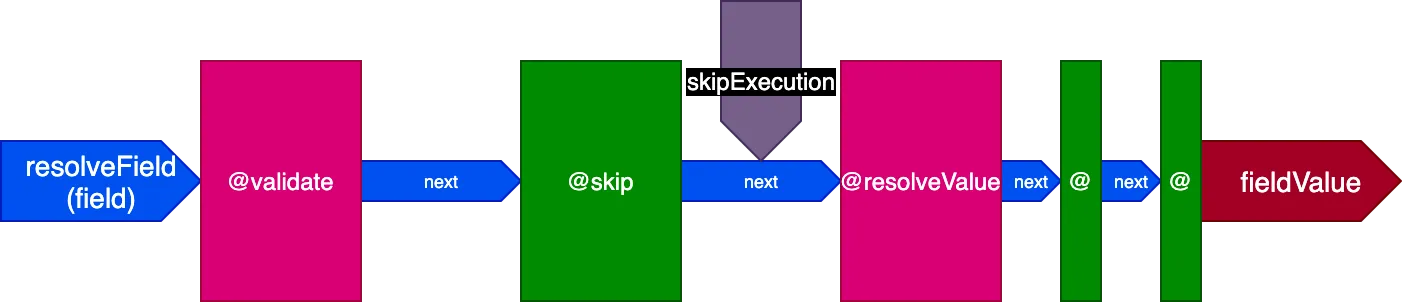
Fíjate en cómo las directivas @skip e @include pueden satisfacerse tan fácilmente con esta arquitectura: situadas en el slot "middle", pueden informar a la directiva @resolveValueAndMerge (junto con todas las directivas en etapas posteriores del pipeline) para que no se ejecuten estableciendo el flag skipExecution a true.
Ejecutar la directiva sobre varios campos en una sola llamada
Hasta ahora hemos considerado un único campo como entrada del pipeline de directivas. Sin embargo, en una consulta GraphQL típica recibiremos varios campos sobre los que ejecutar directivas.
Por ejemplo, en la consulta de abajo, la directiva @upperCase se ejecuta sobre los campos "field1" y "field2":
query {
field1 @upperCase
field2 @upperCase
field3
}Además, dado que el motor de GraphQL añade las directivas de sistema @validate y @resolveValueAndMerge a cada campo de la consulta, de modo que esta consulta:
query {
field1
field2
field3
}...se resuelve como esta otra:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Entonces las directivas de sistema siempre recibirán todos los campos como entradas.
Como consecuencia, el pipeline de directivas está diseñado para recibir varios campos como entrada, y no solo uno cada vez:

Esta arquitectura es más eficiente, porque ejecutar una directiva una sola vez para todos los campos es más rápido que ejecutarla una vez por cada campo, y producirá los mismos resultados.
Por ejemplo, al validar si el usuario ha iniciado sesión para concederle acceso al esquema, la operación puede ejecutarse una única vez. Ejecutar el siguiente código:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}es más eficiente que ejecutar este otro código:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}Esto puede no parecer gran cosa al llamar a una función local como isUserLoggedIn, pero puede marcar una gran diferencia al interactuar con servicios externos, como al resolver endpoints REST a través de GraphQL. En estos casos, ejecutar una función una sola vez en lugar de varias podría marcar la diferencia entre poder ofrecer una determinada funcionalidad o no.
Veamos un ejemplo. Al interactuar con Google Translate a través de una directiva @translate, la API GraphQL debe establecer una conexión por la red. Ejecutar este código será todo lo rápido que se pueda:
googleTranslateFields([$field1, $field2, $field3]);Por el contrario, ejecutar la función por separado, varias veces, producirá una latencia mayor que se traducirá en un tiempo de respuesta más alto, degradando el rendimiento de la API. Posiblemente esto no sea una gran diferencia para traducir 3 cadenas (donde el campo es la cadena a traducir), pero para 100 o más cadenas sin duda tendrá un impacto:
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);Además, ejecutar una función una sola vez con todas las entradas puede producir una respuesta mejor que ejecutar la función sobre cada campo de forma independiente. Volviendo al ejemplo de Google Translate, la traducción será más precisa cuantos más datos proporcionemos al servicio.
Por ejemplo, al ejecutar el código de abajo:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");En la primera ejecución independiente, Google no conoce el contexto de "fork", por lo que podría responder con "fork" como utensilio para comer, como bifurcación de una carretera, o con otro significado distinto. Sin embargo, si en su lugar ejecutamos:
googleTranslate(["fork", "road", "sign"]);A partir de esta cantidad mayor de información, Google puede deducir que "fork" se refiere a la bifurcación de la carretera, y devolver una traducción precisa.
Es por estas razones por las que las directivas del pipeline reciben los campos de entrada todos juntos, y luego cada directiva puede decidir la mejor manera de ejecutar su lógica sobre esas entradas (una ejecución por cada entrada, una única ejecución que abarque todas las entradas, o cualquier opción intermedia).
El pipeline tiene ahora este aspecto:
Ejecutar un único pipeline de directivas para toda la consulta
Hace un momento hemos visto que tiene sentido ejecutar varios campos por directiva; sin embargo, esto funciona bien siempre y cuando todos los campos tengan las mismas directivas aplicadas. Cuando las directivas son distintas, puede dar lugar a una mayor complejidad que dificulte su implementación y reduzca algunas de las ventajas obtenidas.
Veamos cómo ocurre esto. Consideremos la siguiente consulta:
query {
field1 @directiveA
field2
field3
}Esta directiva es equivalente a esta otra:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}En este escenario, los campos field2 y field3 tienen el mismo conjunto de directivas, y field1 tiene uno diferente; tendríamos entonces que generar 2 pipelines distintos para resolver la consulta:
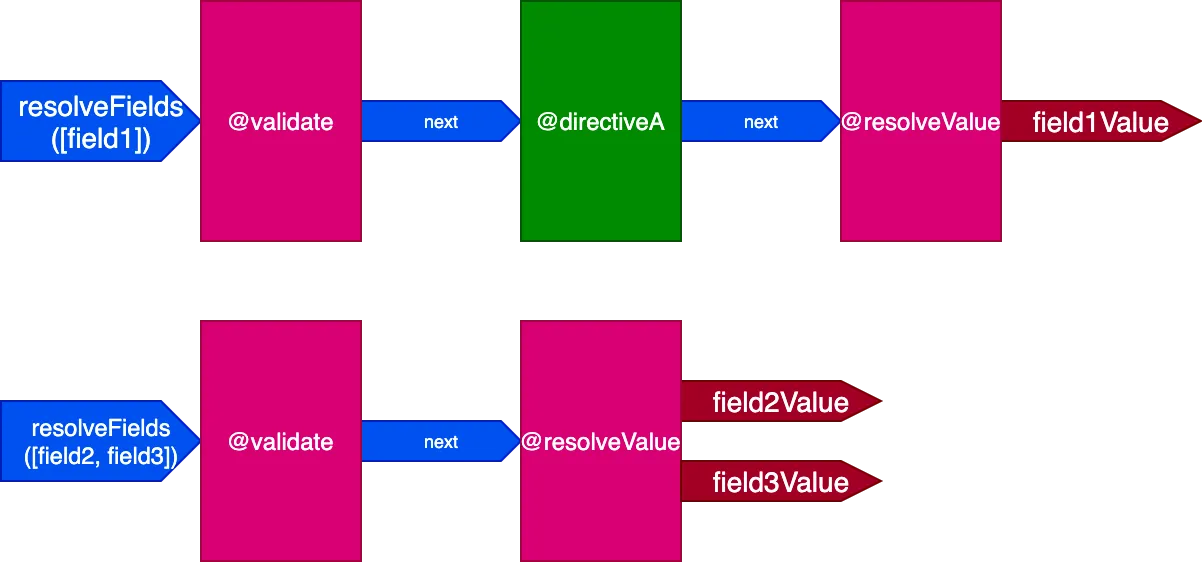
Y cuando todos los campos tienen un conjunto único de directivas, el efecto es aún más pronunciado. Consideremos esta consulta:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}Que es equivalente a esta:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}En esta situación tendremos 3 pipelines para gestionar 3 campos, así:
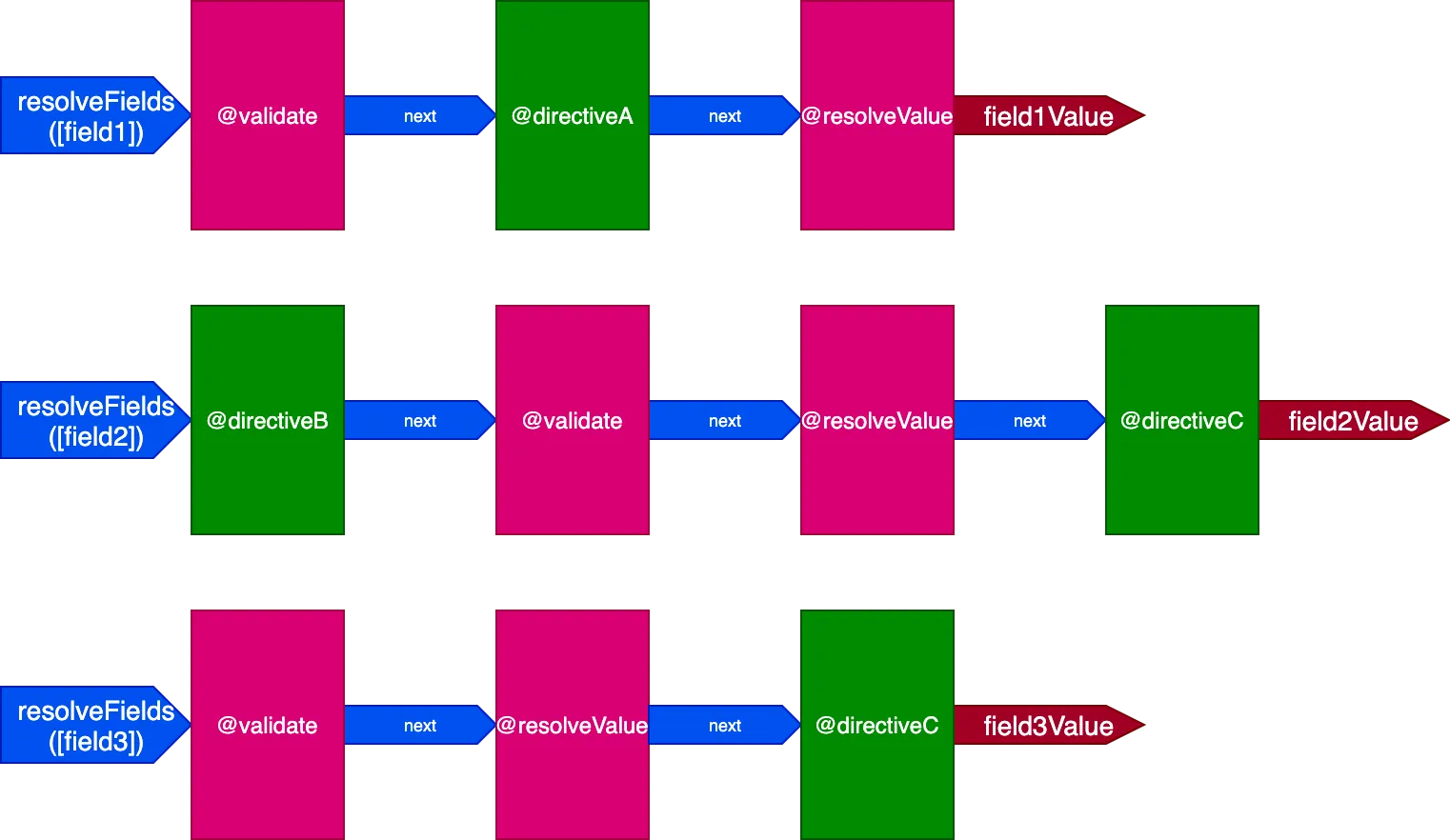
En este caso, aunque las directivas @validate y @resolveValueAndMerge se aplican a los 3 campos, como se ejecutan a través de 3 pipelines de directivas distintos, lo harán de forma independiente unas de otras, lo que nos lleva de nuevo a tener una directiva ejecutándose sobre un único elemento cada vez.
La solución a este problema es evitar producir varios pipelines y trabajar con un único pipeline para todos los campos. Como consecuencia, el motor ya no pasa los campos como entrada al pipeline, ya que no todas las directivas de un único pipeline interactuarán con el mismo conjunto de campos; en su lugar, cada directiva debe recibir su propia lista de campos como entrada propia.
Entonces, para esta consulta:
query {
field1 @directiveA
field2
field3
}...las directivas @validate y @resolveValueAndMerge recibirán los 3 campos como entradas, y directiveA solo recibirá "field1":
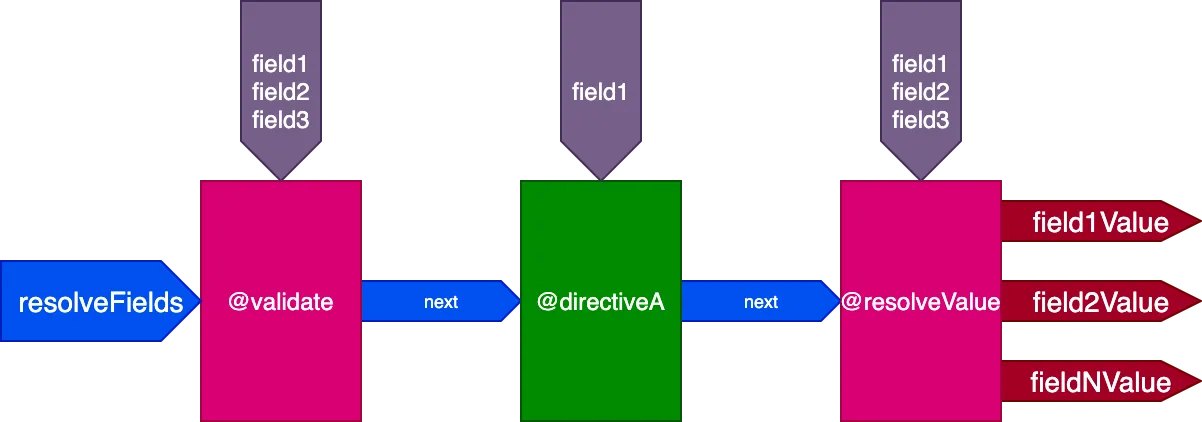
Y para esta consulta:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...las directivas @validate y @resolveValueAndMerge recibirán los 3 campos como entradas, directiveA solo recibirá "field1", directiveB solo recibirá "field2", y directiveC recibirá "field2" y "field3":
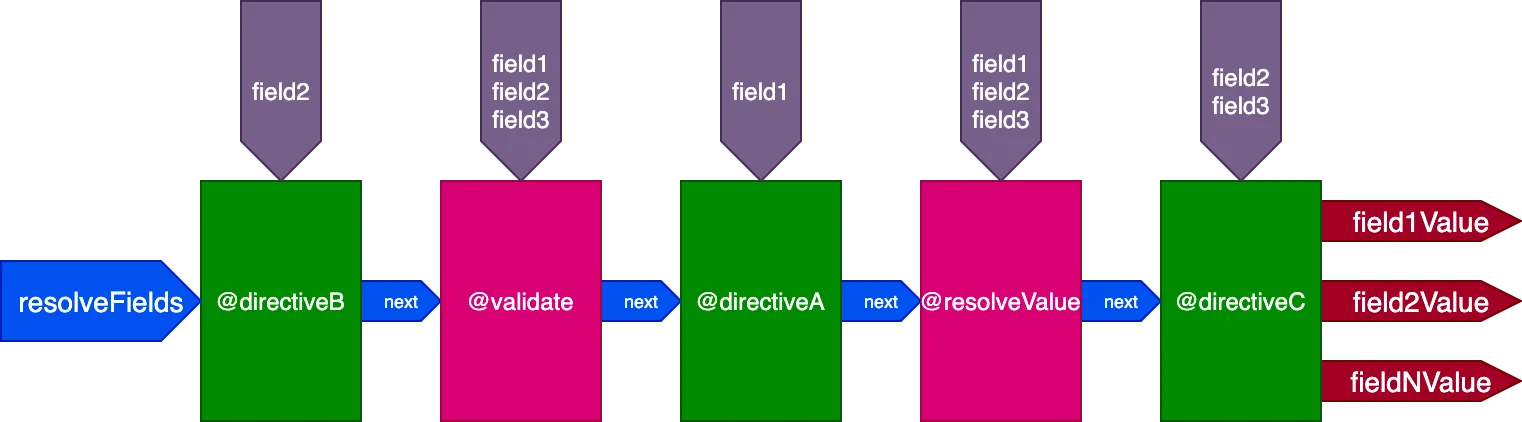
Controlando la ejecución de la directiva ID por ID
Hasta ahora, una directiva en alguna etapa podía influir en la ejecución de las directivas en etapas posteriores mediante algún flag skipExecution. Sin embargo, este flag no es lo suficientemente granular para todos los casos.
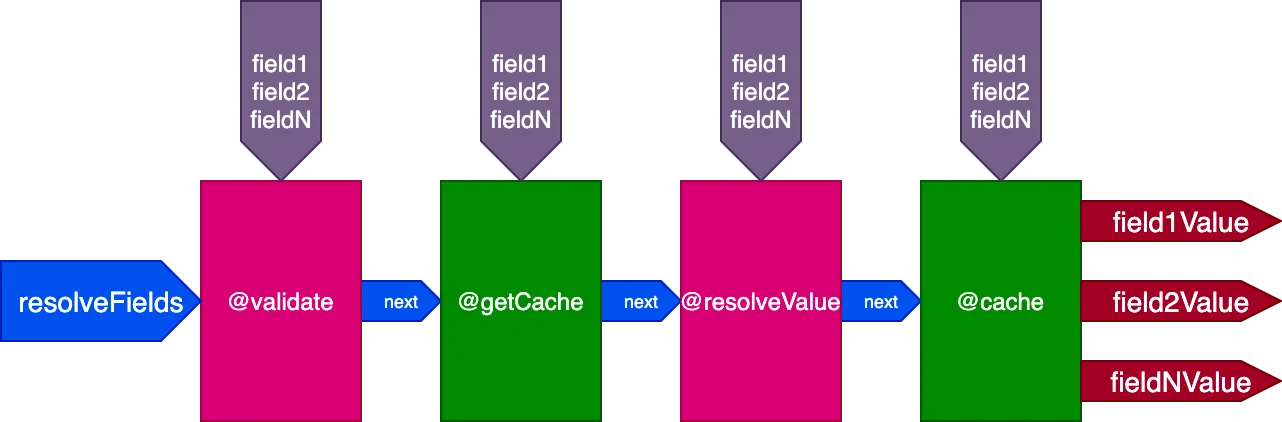
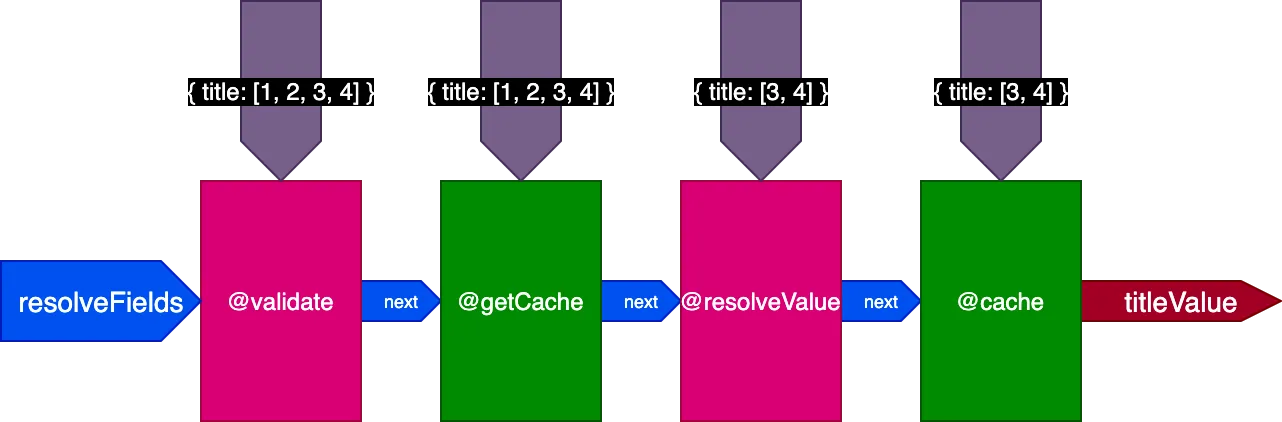
Por ejemplo, consideremos una directiva @cache, situada en el slot "end" para almacenar el valor del campo, de modo que la próxima vez que se consulte el campo, su valor pueda recuperarse de la caché mediante una directiva @getCache situada en el slot "middle":
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}El servidor recuperará y almacenará en caché 2 registros. Después, ejecutamos la misma consulta, pero aplicada a 4 registros:
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}Al ejecutar esta 2ª consulta, los 2 registros de la 1ª consulta ya estaban en caché, pero los otros 2 no. Sin embargo, necesitaríamos que los 4 registros estuvieran ya en caché para poder usar el flag skipExecution. Sería mejor si pudiéramos recuperar los 2 primeros registros de la caché y resolver únicamente los otros 2 registros.
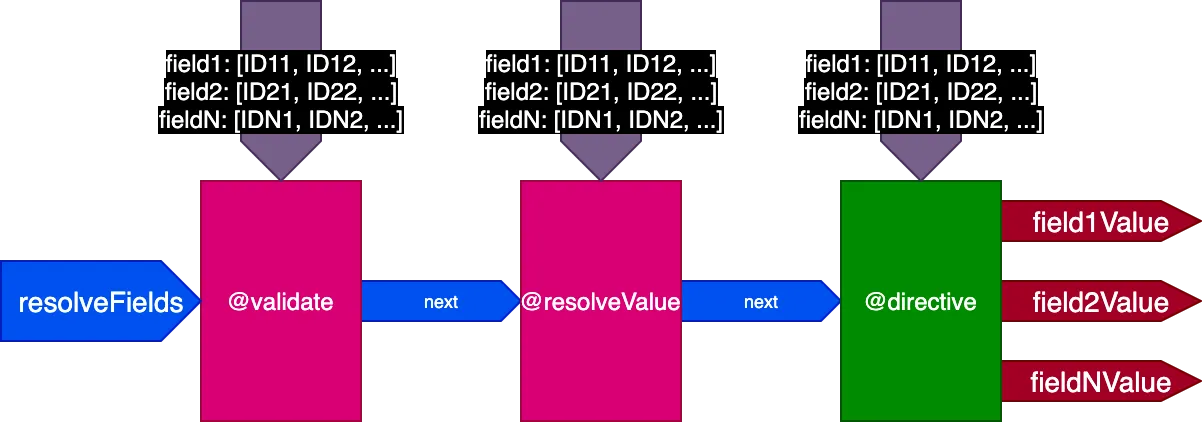
Por eso actualizamos de nuevo el diseño del pipeline. Descartamos el flag skipExecution y, en su lugar, pasamos a cada directiva la lista de IDs de objetos por campo sobre los que debe aplicarse la directiva, mediante un objeto de entrada fieldIDs:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}La variable fieldIDs es única para cada directiva, y cada directiva puede modificar la instancia de fieldIDs para todas las directivas en etapas posteriores. Así, skipExecution puede hacerse de forma granular, ID por ID, simplemente eliminando el ID de fieldIDs para todas las directivas posteriores de la pila.
El pipeline tiene ahora este aspecto:
Aplicado al ejemplo anterior, al ejecutar la primera consulta traduciendo 2 registros, el pipeline tiene este aspecto:
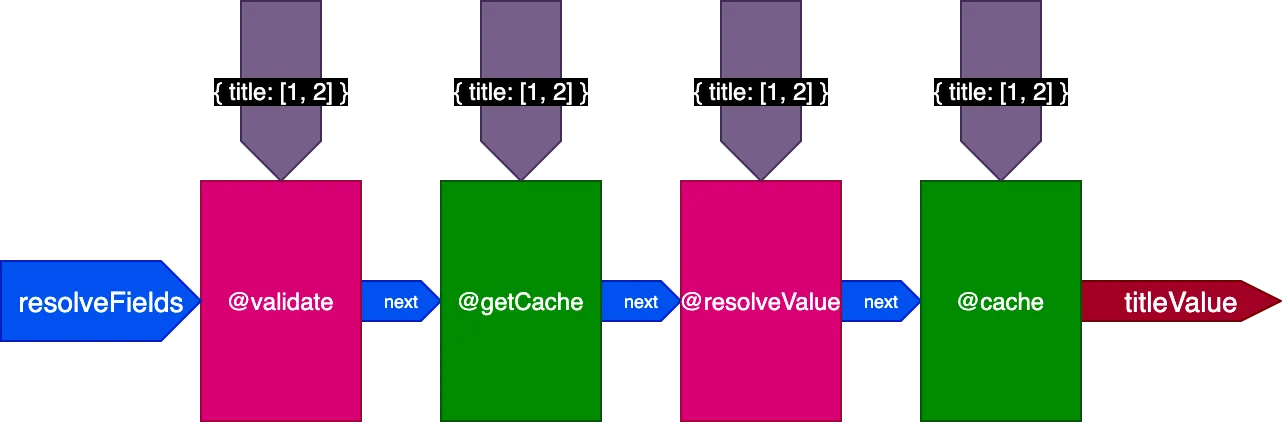
Al ejecutar la segunda consulta traduciendo 4 registros, la directiva @getCache recibe los IDs de los 4 registros, pero tanto @resolveValueAndMerge como @cache recibirán solo los IDs de los 2 últimos registros (que no están en caché):
Atando todos los cabos
Este es el diseño final del pipeline de directivas:
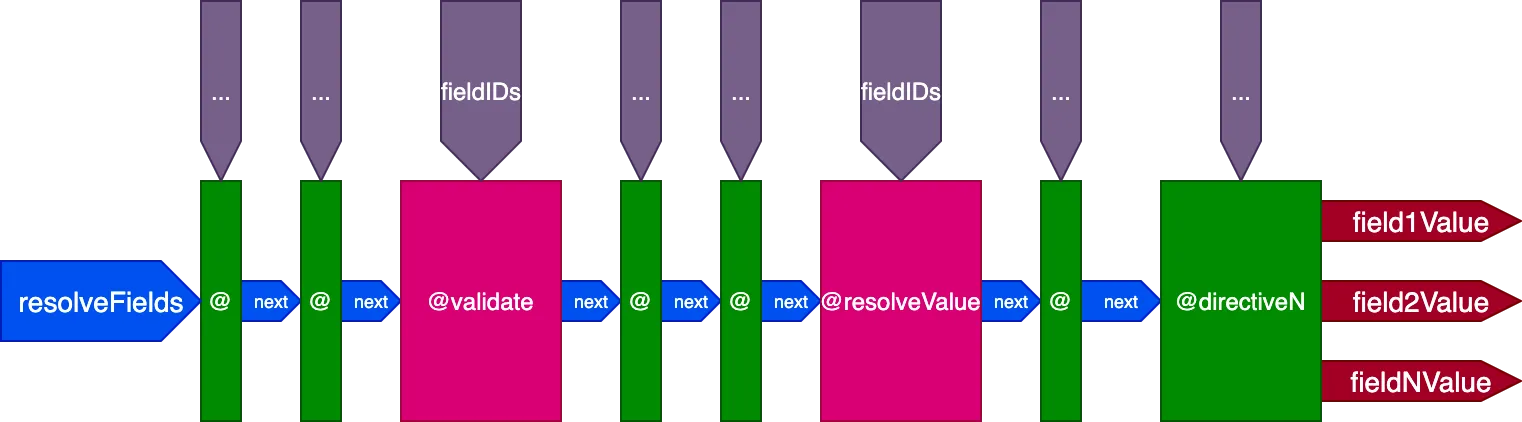
En resumen, estas son sus características:
- Los resolvers de campo se invocan desde el propio pipeline de directivas, a través de las directivas
@validatey@resolveValueAndMerge - Las directivas pueden colocarse en cualquiera de los 5 slots:
"beginning","before-validate","middle","after-validate"y"end" - Las directivas resuelven varios campos en una única llamada
- Un único pipeline contiene todas las directivas involucradas en la consulta
- Cada directiva recibe su propio conjunto de IDs por campo a resolver mediante la variable
fieldIDs - Las directivas pueden modificar la variable
fieldIDspara todas las directivas en una etapa posterior del pipeline